
MiniMind2-Small 全流程尝试#
项目结构:
├── dataset/
│ ├── __init__.py
│ ├── bbc-news-data.csv
│ ├── dataset.md
│ ├── dataset_infos.json
│ ├── dpo.jsonl
│ ├── lm_dataset.py
│ └── rlaif-mini.jsonl
├── eval_llm.py
├── hands-on/
│ ├── sft_eval.ipynb
│ ├── swanlog/
│ └── text-classification/
│ ├── cls_sft.ipynb
│ ├── cls_sft_eval.ipynb
│ ├── cls_sft_old.ipynb
│ ├── en_cls_sft_splitter.ipynb
│ ├── en_pretrain_splitter.ipynb
│ ├── en_sft_splitter.ipynb
│ ├── few_shot1_post.txt
│ ├── few_shot1_pre.txt
│ └── zero_and_few_shots_eval.ipynb
├── images/
├── model/
│ ├── __init__.py
│ ├── model_lora.py
│ ├── model_minimind.py
│ ├── tokenizer.json
│ └── tokenizer_config.json
├── scripts/
├── trainer/
├── out/
├── requirements.txt
└── readme.md第一部分:Pretrain + SFT Pipeline 复现#
硬件:室(活)友(佛)的 RTX 5070Ti 12GB | AutoDL 云 RTX 3090
环境:python 3.11.14
记录+可视化:swanlab
Pretrain#
在 Pretrain 阶段,模型进行无监督学习,模型输出的每一个 token 都会和真实 token 计算 loss.
在 pretrain_hq.jsonl 数据集上从零开始训练了 1 epoch,耗时 ~2hr.
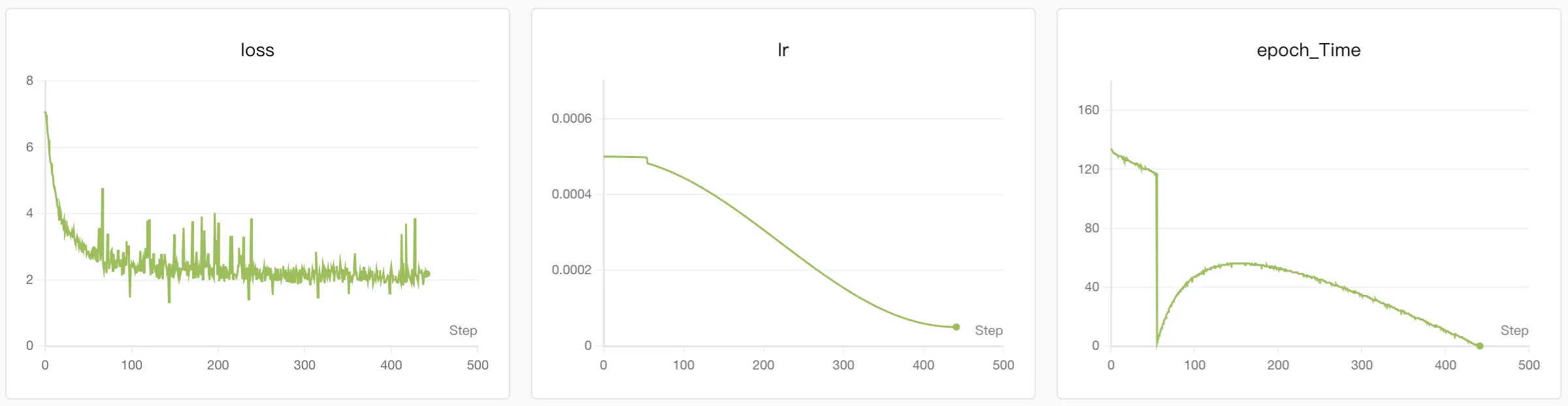
可以看到使用了余弦退火学习率,loss 中后期下降不明显,和原作者的 metrics 吻合。
仅 Pretrain 后的模型对话:
可以看出,模型具备了一定知识和常识,但几乎不懂得以正确的逻辑组织它们。并且模型总是输出很长,且把训练文本里用户的 prompt 当做需要输出的部分。
另外,由于 pretrain 测试集中没有英文,因此英文能力基本没有。
SFT#
在 SFT 阶段,模型会被训练对话能力,因此模型对 prompt 的“下一 token 预测”将不会被计算 loss,而只对模型自己输出的内容与我们期待它输出的内容计算 loss. 这种计算序列的一部分的 loss 是通过 mask 实现的。
在 sft_mini_512.jsonl 上 SFT 了 2 epochs,耗时 7hr.
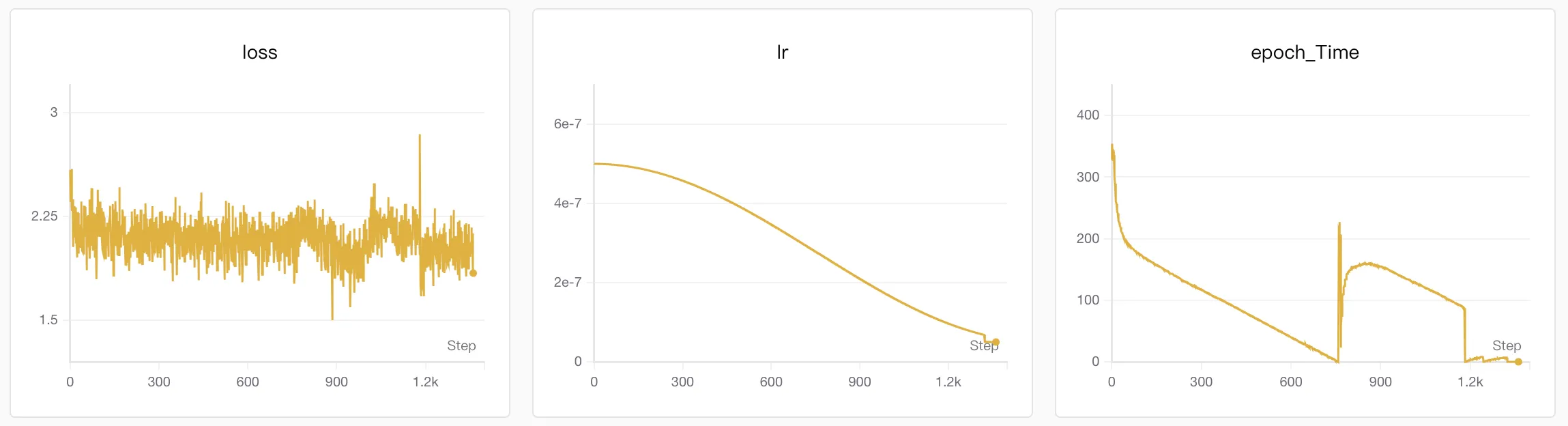
这一次,由于仍然是使用的英文极少的数据集,所以英文能力几乎没有提升。
尝试使用过
sft_512.jsonl(含有更多英文样本)进行 SFT,但手头的笔电内存带不动 qwq.
第二部分:模型架构理解#
Tokenizer#
将经常高频出现在一起的字符(或者字节)聚合成一个 token,通过增加 vocab_size 来换取训练/推理时更少的 token 序列长度,节省算力且利于收敛。同时,token 内含一些基本的统计规律,更有利于模型学出语义信息。
Tokenizer 通常是离线单独训练的, 会实现设定一个“最大词表大小”,然后从字符级或字节级的单位出发,每次将连续出现概率最高的一对 token 合并成一个 pair,加入到词表中(注意不会删除合并前的 token),这样词表会变大,当达到上限时停止合并,就完成了 tokenizer 的训练。
刚刚提到的“字节级” Tokenizer,即 BPE 分词,可以有效避免出现模型没见过的 token(OOV)。
在模型本体训练/推理的时候,Tokenizer 做的仅仅是分词+给每个词打上独特的编号,其本身的参数不再改变。
当然,也存在新型的跟随模型训练的 end-to-end Tokenizer,不过不是主流。
Embedding#
从 Tokenizer 那里拿到了 token 对应的编号,如果用传统的 one-hot 编码,每个 token 都是正交的,模型难以构建词之间的语义联系,因而也就无法使用 attention 机制。此外,one-hot 也过于稀疏,导致网络参数量爆炸。
因此引入一个 Embedding 层,把 token 映射成比纯编号稀疏、又比 one-hot 稠密的向量。这个 Embedding 层通常跟随模型一起训练,但也可以提前单独训练一个 Auto Encoder,再取其中下半部分作为 Embedding 层。
从结果上来看,embed 向量的大小、方向、相对位置常常与语义有一定联系,比如相近的 token 常常被映射到相近的向量,具有类似关系的 token 的相对位置也类似……
Embedding 层就是一个从 token 编号到 embed 向量的表格,框架实现是直接查表,相比使用 one-hot 向量与 Embedding 矩阵做矩阵乘法性能更优。
位置编码#
Sinusoidal 编码#
在 Attention is all you need 论文中,位置编码使用的是 Sinusoidal 编码,将一个类似于在高维空间中,在不同轴向以不同速率旋转的向量叠加到 embed 向量上,并期望上层模型能学习到提取位置特征的能力。得益于这种方式的数学结构(高维旋转),它保证了只要两个 token 间隔距离相同,那么无论它们的绝对位置如何,其位置编码的”相位差“恒定。因此我们期望模型能稳定地学出相对位置的特征。
美中不足的是将位置编码和 embed 向量直接相加,导致模型分离二者时可能出现困难。
RoPE 编码#
不像 Sinusoidal 那样给 embed 向量加上位置编码,RoPE 选择在 embed 向量经过 QKV 矩阵、成为了 qkv 向量之后再编码位置。这意味着,RoPE 的位置编码只在点积算相似度的时候起作用,而不会被任何可学习的矩阵处理! 这看起来限制了模型理解位置的潜力,但事实证明效果更好。
RoPE 直接旋转 q 和 k 向量,而不是叠加一个旋转向量。具体地,它对 q 和 k 向量的不同维度做不同频率的旋转,然后进行 scaled dot product,作为权重对 v 进行加权。
RoPE 的好处是,它不改变 QKV 矩阵得到的 embed 向量,确保了语义信息的保真。同时,直接对向量进行旋转具有更好的”相对位置“特性,位置差和相位差的映射固定。
除此之外,RoPE 只旋转向量、不叠加向量,有利于模型泛化到训练时未曾见过的更长的序列上(extrapolation),而不必担心模型不认识大位置的编码。
而且,RoPE 的数学性质还导致其具有远程衰减性,但数学推导过于复杂,我没太看明白。
可学习的位置编码#
BERT 采用了这种编码。但在 LLM 中使用较少,因为会增加计算量+提升不明显+增加过拟合风险+难以 extrapolate。
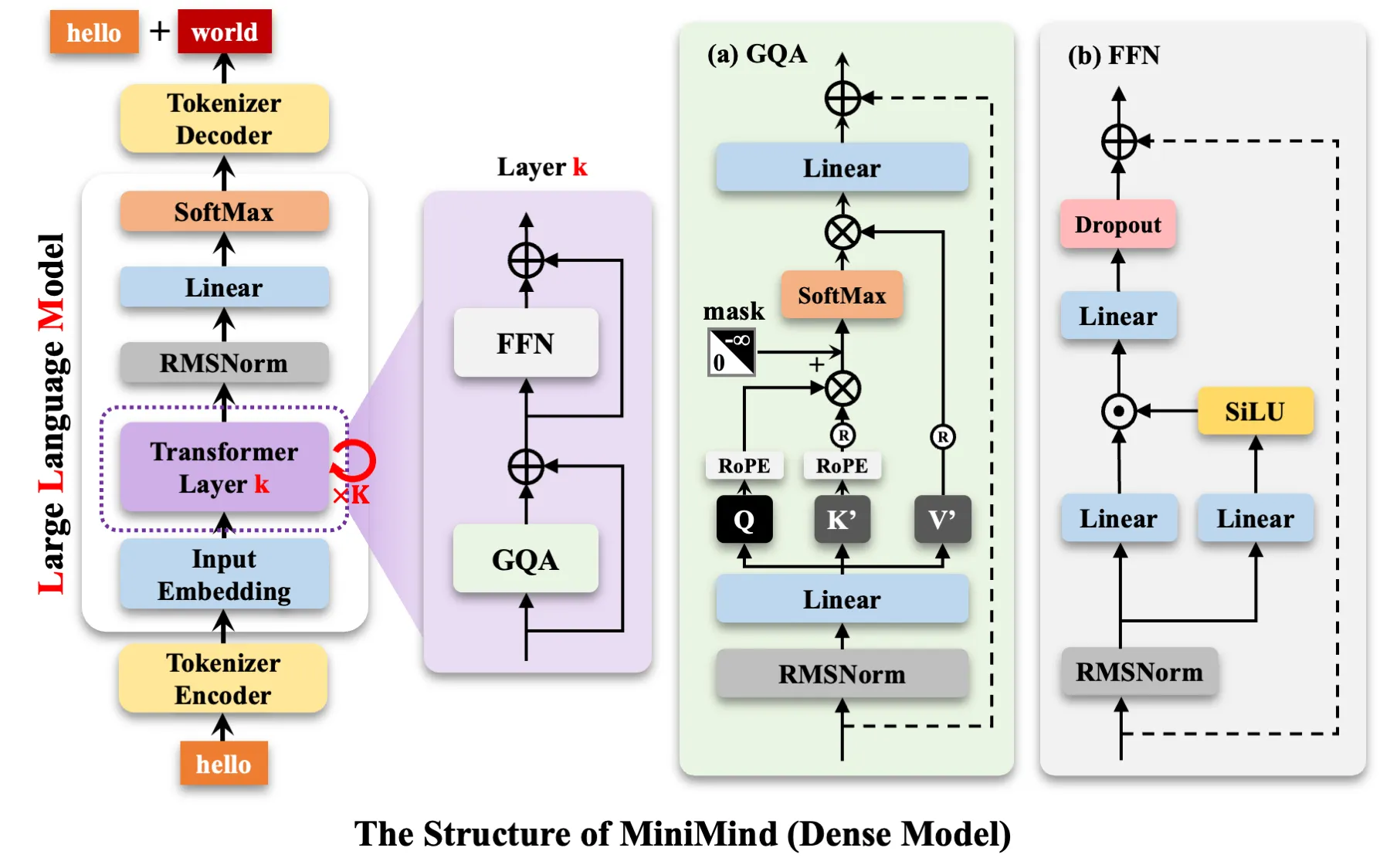
Transformer Block#
本质上还是 self-attention + normalization + ffn + normalization,其中穿插着残差连接。只不过其中的 attention 部分换成了参数更少的 GQA,normalization 换成了 RMSNorm.
GQA#
原本的 multihead attention 是有多组 qkv,q 和 k 一一对应。
但我们发现 k 冗余较多,使得模型参数量、计算量都有浪费。
GQA 的做法是将多组 query 组成一个 group,一个 group 对应同一组 key 上,减少了 K 矩阵的数目,降低了模型参数量,也降低了以及 key 的计算成本,并且有利于 KV Cache.
比 GQA 更加激进的是 MQA,直接只生成一组 key,所有的 query 都在这组 key 上查询。
FFN#
使用了 SwiGLU 门控,有点类似 GRU/LSTM. Gate 的作用是给线性层输出加上了“乘性”表达能力,这种能力是无法完全用单一矩阵拟合的(矩阵只是线性组合)。
其中的 SiLU 激活函数有有很多优点:
- 解决了 dying ReLU 问题,负区间梯度不会直接截断
- 提供了更加平滑的梯度,从而有更精细的表达能力,同时在深层反向传播时更稳定
- 在负区间不单调,表达能力更强
- 形状类似 Sigmoid-GELU,而其计算成本有所减小
Normalization#
现代 LLM 使用 RMSNorm(只进行缩放) 代替 Transformer 原始论文中采用的 LayerNorm(同时归一均值和方差),并且从“对输出进行归一化”转向“对输入进行归一化”。
一方面,RMSNorm 计算量更小;另一方面,RMSNorm 不像 LayerNorm 那样会改变向量方向,从而使得语义在模型中的流动更保真。
对于 post-LN 向 pre-LN 的转变,其好处在于从一开始训练,网络接受到的就都是归一化之后的输入,因此不需要在开始时有意从小 lr 开始进行 warm-up.
残差连接#
最早在 ResNet 中使用,效果是加速了深层模型的收敛并提高了深层模型的稳定性和训练效果。对它的原理有多种解释:
- 它保证了网络整体的性能不比网络的一部分差,即允许底部网络通过残差连接绕过上层,保证整体网络的性能至少大于等于底部的网络。
- 按照何恺明的论文,ResNet 原始的目标是允许上层的梯度在反向传播的时候能更直接地传回下层,加快下层更新速度。
- 模型的拟合能力是随着层数的增加由粗略到精细的。假设下层已经建立了对数据的粗略拟合,那么残差连接就是让中间的层(设为 F)专注于“精雕细琢”,即 F 要拟合出一个 Δx,使得 x+Δx 相比于 x 是一个更精细的拟合。这样训练 F 往往比让 F 直接拟合出 x+Δx 更容易。
Mask#
模型在多个位置都会使用到 mask(掩码)。
Mask 按照作用方式可分为两种:Attention Mask 和 Loss Mask.
- Attention Mask 作用在每一层的注意力分数与 softmax 之间,用于将注意力不应关注的位置(比如 padding、prompt)从 key 中排除出去。具体做法是,对于 矩阵(其中每一行表示一个 query,每一列表示一个 key),将特定的列置为负无穷,从而保证 softmax 计算结果的对应位置是 ,取消该 key 对注意力的影响。
- Loss Mask 则是在模型输出时,决定我们要优化模型输出的哪一部分,而将其余部分置之不理。换句话说,就是决定哪些 token 受监督、需要计算反向传播。比方说,模型接受了用户的 prompt,需要输出回复。由于模型一般对整个序列进行并行的输入输出,因此模型会同时输出它对 prompt 中下一个 token 的预测,以及它自己生成的回复。此时我们就可以使用 Loss Mask 来只优化模型自己输出的部分,而不管模型在 prompt 上进行的“预测”。
除了上述分类,Mask 还可以按照目的可以分成三种:Causal Mask, Padding Mask, 和 Supervision Mask.
- Causal Mask 的作用是在生成式 transformer 模型训练时,允许 token 之间并行处理而同时又保证每个 token 只参考其前面的 token 的信息;在推理时,Causal Mask 的作用能被隐式保证,因此可以不加。简单理解就是,Causal Mask 在并行的 token 间强行创造了时序. Causal Mask 是一种 Attention Mask.
- Padding Mask 只有在存在 Padding,也即存在“对齐需求”,也即存在 batch 的时候起作用。其主要目的是将一个 batch 中长短不一的输入对齐成相同长度,以便 GPU 并行处理。但填充的 <pad> 没有实际意义,不应该被 attention 注意到,因此需要被 mask 掉。Padding Mask 也是一种 Attention Mask.
- Supervision Mask,几乎可以等同于前述的 Loss Mask.
第三部分:更多实验#
Hyperparameter Tuning#
训练时#
训练调参太贵了吧,尤其是预训练。。。。。。
哎,原来只有我是穷人。
由于 AdamW 对学习率确实不太敏感,取 1e-5 至 5e-3 之间,配合余弦退火,差别不大。
那么就是根据显存调一调 batch_size,以及根据时间成本选择一下 epoch 数。
推理时#
温度#
温度是在模型最终输出的 softmax 前,给 logits 加上的系数。具体地,当温度为 时,每个 logit 会变为 . 可见,温度越小,logits 的绝对值越大,对应到 softmax 的结果就是概率越集中于最大值,趋近于 argmax,模型在采样时也就越不可能输出最大概率以外的 token.
实验表明,当温度设置得较低的时候,如 0.3,模型倾向于输出重复、冗长的话,换句话说,模型每一步都倾向于输出“前几个 token 中的某一个 token”,并且难以输出 <eos>.
为测试方便,我使用了 MiniMind2 自带的 8 个标准测试问题:
0. 你有什么特长?
- 为什么天空是蓝色的
- 请用Python写一个计算斐波那契数列的函数
- 解释一下”光合作用”的基本过程
- 如果明天下雨,我应该如何出门
- 比较一下猫和狗作为宠物的优缺点
- 解释什么是机器学习
- 推荐一些中国的美食
同时,所有测试均进行在前述第一部分中得到的那个模型上,统计模型的输出长度(字符数)和 4-gram 重复率。
def ngram_repetition(tokens, n=4):
ngrams = [tuple(tokens[i:i+n]) for i in range(len(tokens)-n+1)]
counts = Counter(ngrams)
total = len(ngrams)
repeated = sum(c for c in counts.values() if c > 1)
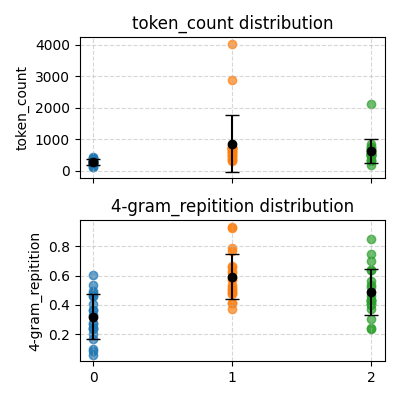
return repeated / total if total > 0 else 0下图是 temperature=0.3 的情况,平均 token 长度为 335.492424,平均 4-gram 重复率为 0.660548:
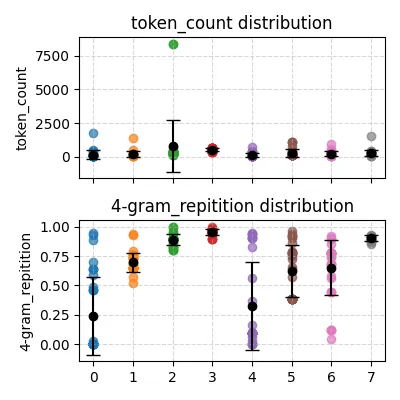 特别地,我保存了模型某一次的回答,可以看到模型确实一直在重复最后的几个 token:
特别地,我保存了模型某一次的回答,可以看到模型确实一直在重复最后的几个 token:
下图是使用 temperature=0.85 (模型默认)的情况,平均 token 长度为 332.098485,平均 4-gram 重复率为 0.360656:
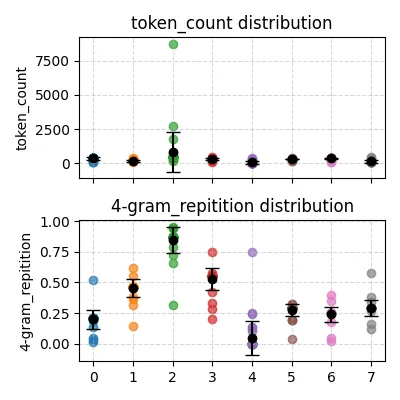 可以看到,模型重复地说废话的趋势明显受到了抑制,但输出长度没有明显变少。
可以看到,模型重复地说废话的趋势明显受到了抑制,但输出长度没有明显变少。
此外,可以注意到模型对第三个问题的回答始终不好(虽然我们的统计方法可能对“生成代码”类问题不友好,但实际上经过更仔细地测试,模型确实没有学会写代码)。
最后,还有一个使用 temperature=1.7 的测试:
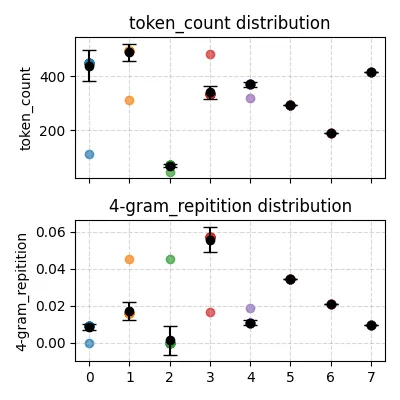
可以看到重复率低了很多!但输出长度变化仍然不大(除了第三个问题)。
那么,这是否意味着模型的效果很好呢?完全不是,我们可以看看它到底输出了什么:
Top-K Top-P#
Top-K:每次随机采样时,只在概率最大的前 top_k 个 token 中采样,其余概率置零。
Top-P:每次随机采样时,将候选 token 按概率由大到小排序,从概率最大的开始,依次取出若干 token,使它们的概率之和刚好等于或超过 top_p.
下面尝试在保持默认温度(0.85)下,减小 Top-P 的值,期望提升模型的理工科能力。
注:以下测试基于官方 MiniMind2-Small 模型权重,而非我自己训练的模型。这是因为我自己训练的模型没有使用足够的数据、没有积累足够长的训练时间,实际效果不佳。
测试用的问题:
0. 为什么天空是蓝色的
- 请用Python写一个计算斐波那契数列的函数
- 解释一下”光合作用”的基本过程
GPT 在这三个问题上的回答(使用临时对话)的统计数据:
| 问题 0 | 问题 1 | 问题 2 | |
|---|---|---|---|
| token_count | 443 | 830 | 809 |
| 4-gram_repetition | 0.05 | 0.6964 | 0.2196 |
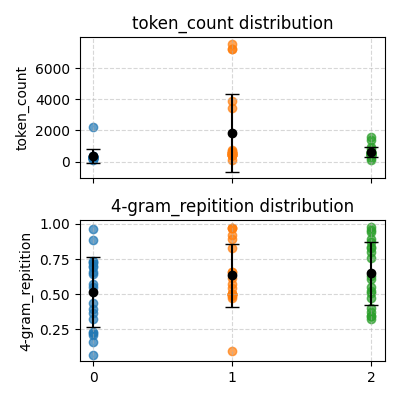
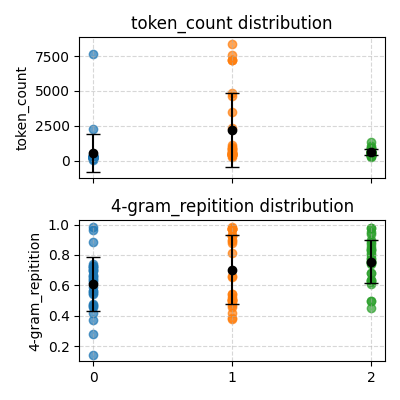
从上面可以看出,低 Top-P 会一定程度上促进模型输出重复的 token,但从 0.55 下降到 0.3,这种现象反而有所减轻。
此外,可以注意到我们的评判方式对编程题目不太客观,因此我还针对编程类问题,尝试创造一种更有效的评判标准:具有远程衰减的 n-gram 重复度。
这个标准基于一个思想:代码中应当允许有意义的重复,比如函数的反复调用、变量的多次操作等。因此我们需要从所有的重复中分离出有意义的和无意义的,一个关键点就是两个重复 token 之间的距离。这个评判标准会惩罚近距离的密集重复,但会宽容稀疏的重复(更可能是有意义的)。代码如下:
def weighted_ngram_repetition(
tokens,
n: int = 4,
window: int = 50,
window_is_token_distance: bool = False
):
ngrams = [tuple(tokens[i:i+n]) for i in range(max(0, len(tokens) - n + 1))]
M = len(ngrams)
if M == 0:
return 0.0, []
if window_is_token_distance:
window = max(0, window - n + 1)
# 记录每种 ngram 出现的位置(sorted lists)
positions = defaultdict(list)
for idx, ng in enumerate(ngrams):
positions[ng].append(idx)
activations = [0.0] * M
max_local = 1
for ng, pos_list in positions.items():
for p in pos_list:
left = p - window
right = p + window
L = bisect.bisect_left(pos_list, left)
R = bisect.bisect_right(pos_list, right)
count = R - L
if count > max_local:
max_local = count
# avoid division by zero
denom_global = max_local
for ng, pos_list in positions.items():
# pos_list sorted ascending
for p in pos_list:
left = p - window
right = p + window
L = bisect.bisect_left(pos_list, left)
R = bisect.bisect_right(pos_list, right)
local_count = R - L # 包含自身
start = max(0, p - window)
end = min(M - 1, p + window)
theoretical_max = end - start + 1
denom = denom_global if denom_global > 0 else 1
activation = local_count / denom
activations[p] = activation
# 全部位置的平均激活值作为最终 score(在 0..1 之间)
score = sum(activations) / M
return score这段代码在求:对于每个 n-gram,在其周围半径为 window 的邻域内,同种 n-gram 的占比。以这个占比作为该 n-gram 的激活值(值域为 0~1),然后再按照之前的统计方法求和再除以总 n-gram 数。
测试问题还是:“请用Python写一个计算斐波那契数列的函数”。
GPT 的回答作为标准参考(使用临时对话),其数次回答的 W4R 平均值为 0.016878166477133128.
而我们的 MiniMind2-Small 模型在不同 Top-P(0.85, 0.55, 0.3) 下的表现:
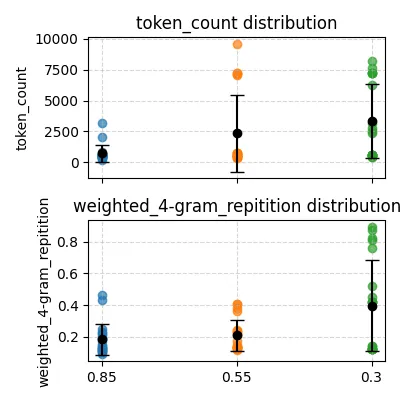
可以看到,Top-P 确实会影响模型的代码输出质量,其作用和温度类似(这点从理论上也可以预见)。
束搜索#
需要注意的是,MiniMind2 源码采用的是随机 sampling,和束搜索使用的半贪心策略有所冲突。所幸 transformers 库包含了 beam search 的实现,因此只需要小改一下代码,在 model.generate 中设置 do_sample=False 以及 num_beams 参数。
Text Classification#
本节内容使用 MiniMind2-Small 和 MiniMind2 作者发布的权重,基于此进行 zero-shot,few-shot,以及文本分类的 Fine Tune.
Zero-Shot#
首先尝试 MiniMind2-Small,使用指令:
Please read the following passage and classify it into one of five types: business, entertainment, politics, sport, tech.效果不佳,模型完全不知道要输出五个词中的一个,而是输出无关长文本。
于是切换到 MiniMind2,并换用更加有约束的指令:
Classify the passage you will read. You MUST choose exactly one of the following categories:
business, entertainment, politics, sport, tech.
title:
{title}
content:
{content}
Your answer (choose ONLY one category in business, entertainment, politics, sport, tech):十分可惜,模型虽然意识到输出中要出现这五个词之一,但是仍然以为是续写文本,输出很长的废话,似乎想要续写提示词而不是回答问题。
Few-Shot#
在提示词中加入一些分类示例。我们期待:即使模型试图“续写”,它也应该知道续写成什么样子。提示词格式:
You are a text classifier. Classify each passage into **exactly one** of the following categories:
- business
- entertainment
- politics
- sport
- tech
Output **only the label**, nothing else.
Here are some examples:
Example 1:
title:
{example1_title}
content:
{example1_content}
Your Output(Must be one of "business entertainment politics sport tech"):
{example1_category}
...
Example 6:
title:
{real_title}
content:
{real_content}
Your Output(Must be one of "business entertainment politics sport tech"):其中一个巧妙想法是:将真实输入伪装成 Example 6,诱导模型以续写的方式输出。
很可惜,这回模型是学会了只输出单个单词,但是仍然胡乱输出,输出的并非分类标签。
不行了,这下必须上 SFT 了!
SFT#
这部分是基于 MiniMind2-Small 在 pretrain_hq.jsonl(几乎纯中文) 上预训练出的模型进行微调的。
数据集:bbc-news-data.csv,通过脚本将每类按 4:1 比例随机采样分成训练集和测试集,然后使用之前的 instruction 模板包装一下 title content 等字段,即可开训!
下面是一部分结果:
| Epoch | Accuracy |
|---|---|
| 2 | 0.05 |
| 6 | 0.2 |
在之后的 epoch 中,accuracy 没有继续提升,让我十分沮丧。
我观察了模型的输出,发现它似乎放弃了理解内容,而是每次都倾向于输出 sport(也解释了接近 1/5 的准确率)。
呜呜呜调死我啦,怎么改都提升不了。
谁懂凌晨两点盯着 AutoDL 上不断减少的余额时的救赎感啊。。。
大道都磨灭了
由于调参甚久,且我以广度优先的方式尝试了很多方法,因此这里无法展示所有中间产物,只讲成品。
终于调出来啦啊啊啊啊啊
Text Classification 二周目#
在上一节中模型效果很差。我考虑了很多因素,最终归因于模型预训练的语言(中文)和分类所要使用的语言(英文)差别过大。这就导致了预训练模型对英文一窍不通,只能瞎蒙。因此,我们需要在纯英数据集从头上训一个 Pretrained MiniMind2-Small.
这种数据集哪里找呢?真是——踏破铁鞋无觅处,得来全不费工夫!先去逛了一大圈 CSDN 和知乎,看到的动辄都是 Wikimedia 这种超大数据集,完全不现实。但我灵机一动,重新精读了一遍 MiniMind2 仓库的 readme.md,发现里面提到了匠数大模型数据集,正好有纯英数据,只不过是 sft 专用的,每一条都包含很多轮对话。不过不要紧,我在其中随机采样 10% 的对话,然后每段对话直接拼接成单个长文本,就可以作为预训练数据集啦。
预训练了 3 epochs 后,先看看模型的输出。
询问 Please write a code to calculate the sum of all odd positive integers smaller than 100,模型完全理解了英文意思,并且输出了有模有样的 C++ 和 Python 代码(但代码有些语法问题,毕竟是“文科生”)。不过输出特别长,这是因为我们数据集是拼接的多轮对话,导致模型一直学习到这种超长文本。
模型底子打好了(相比基于 pretrain_hq.jsonl 预训练的模型,新模型英文能力极强),接下来就是重新进行文本分类实验的三个部分了。
Zero-Shot²#
在 Pretrain 的基础上,使用英文对话进行 2 epochs 的问答 SFT,然后使用分类指令让模型分类,效果相比之前依然很烂。模型在测试集上只误打误撞做对了一个预测,这很可能是因为模型没有理解什么是“分类”。
Few-Shot²#
使用和 Zero-Shot² 中一样的 SFT 模型,给予 5 个类别各一个 example,然而模型仍然没有理解分类任务的含义。也许是小模型泛化能力过低,或者对话训练次数过少,没有习得理解这种指令的能力。
SFT²#
当 context learning 不奏效的时候,还得祭出梯度下降大法!
全参数微调#
使用在前述的在英文数据集上预训练的模型,在 bbc-news-data 上有监督微调了 10 epochs,最终模型在测试集上的准确度达到了 79%!
下方是模型在测试集上的预测矩阵,纵向为真实值,横向为预测值。
从中可以看出哪些分类本身比较接近,而那些区别非常显著。
| real\pred | business | entertainment | politics | sport | tech |
|---|---|---|---|---|---|
| business | 92 | 2 | 6 | 0 | 2 |
| entertainment | 1 | 61 | 6 | 4 | 3 |
| politics | 13 | 8 | 60 | 0 | 2 |
| sport | 1 | 16 | 6 | 74 | 0 |
| tech | 9 | 3 | 6 | 1 | 57 |
上半层微调#
尝试冻结 Embedding 和下方 50% 的层,只训练上部,以期节省时间。
与全参数微调中的训练流程相同,最终模型在测试集上的准确度达到了 67%. 能力确实有所下降,但对训练用时的缩减作用不明显。大概只有在模型规模很大,而微调数据集较小的时候,冻结参数才能发挥其节省时间、减轻过拟合的作用。
下方为其预测矩阵:
| real\pred | business | entertainment | politics | sport | tech |
|---|---|---|---|---|---|
| business | 83 | 8 | 8 | 2 | 1 |
| entertainment | 1 | 47 | 7 | 16 | 6 |
| politics | 13 | 17 | 47 | 5 | 1 |
| sport | 2 | 20 | 4 | 66 | 3 |
| tech | 11 | 4 | 9 | 5 | 48 |
LoRA#
这同样是一个在大模型上作用明显,在小模型上体感不明显的方法。它的概念就是,在 SFT 的时候,不直接修改模型参数,而是给每个线性层加上一个补丁,这个补丁的参数量很小(秩很低),通过训练补丁来起到模型能力迁移的关键作用。
我测试了 rank=8,32,128 三种情况,随着 epoch 增加,loss 均没有明显下降。只有当 rank 增加到 1024(折合模型总参数的约 40%)的时候,才有可观察的效果。最终,在测试集上准确度达到 40%,附预测矩阵:
| real\pred | business | entertainment | politics | sport | tech |
|---|---|---|---|---|---|
| business | 47 | 45 | 6 | 0 | 0 |
| entertainment | 3 | 66 | 2 | 1 | 3 |
| politics | 20 | 32 | 22 | 1 | 1 |
| sport | 13 | 59 | 1 | 13 | 2 |
| tech | 14 | 30 | 5 | 1 | 14 |
如何更有性价比地提升精度?#
Multi-agent Debate:成本暴涨,且小模型自身能力瓶颈,通过该方式缓解不如扩大模型。
Prefix Tuning:加一段可训练的软 prompt,以诱导模型做出更好输出。但在小模型面对复杂数据时,容易欠拟合,作用微弱。
根据 GPT 的建议,可以尝试将分类标签的 token 设置为 special_token,保证其长度相同,并使用 logits 中分类标签的排名而不是模型自行输出的文本来分类。
然而,这样做出来的效果竟然只有 39% 的准确度,目前暂且认为是代码实现里有些隐性的 bug.
更多以后要探索的部分#
了解到 Hugging Face 的 PEFT 库,有时间研究一下。
RLHF#
理论#
我理解的强化学习在这里的作用,类似于一种对「不可微分的 loss function」的一种 workaround 训练方式。
通常,我们在训练序列生成模型的时候,会对每个时间步的预测使用 CrossEntropyLoss 进行损失评估。这种损失函数是可微分的,因此才能够梯度下降进行训练。但是很多时候,模型表现的好坏与交叉熵的数值关系不大,我们会希望找到更精准、更灵活的评估模型好坏的函数。
譬如,我们会使用 BLEU score 衡量翻译模型的能力,但是 BLEU score 本身不可微分,无法梯度下降。这时候就需要 Reinforcement Learning 出手,让模型自行试错并找到让 BLEU score 高的生成模式。
对于聊天机器人来说,其服务对象是人,因此使用人的反馈(显然无法微分)进行强化学习训练,让模型微调到在人类看来表现更佳的 pattern 上去。
DPO 的做法是,把模型复制成为两份,一份作为参考(ref),一份进行训练(policy)。每次将一个好的回答(chosen)和坏的回答(rejected)喂给二者,比较二者输出 chosen 的概率与输出 rejected 的概率。具体地,是把这两种概率求对数(避免累乘导致下溢),然后除以序列长度,再做差,这个差距称为 logratios(越大越好)。训练的目标是让 policy 模型的 logratio 比 ref 模型的大。
损失函数公式为:
其中的 是一个超参数, 是 sigmoid 函数。
实践#
使用 MiniMind2 提供的 train_dpo.py,从Zero-Shot²中得到的在英文数据集上进行 Pretrain 和 SFT 过的模型权重开始,进行 DPO.
使用 1e-7 学习率训练 1 epoch 后,实测模型确实尝试变得更加“友好”,但其语言水平和技能出现倒退(应该是学习率过大导致的遗忘?),尤其是写代码能力,退化严重,只能输出重复字符。
咨询了 GPT,得到了肯定的答复:
强度过高的 DPO 会导致模型专业能力显著下降。
代码是 最容易被 RLHF 破坏的能力之一,原因有三:
代码的“人类偏好”极不可靠
- 人类评审:
- 更看重“看起来对”
- 而非严格正确
- 长代码 vs 短代码:
人类往往选解释多的
- DPO 对「概率差」极其敏感
只要模型发现:
“写详细解释 + 保守代码 比写短小精悍的代码更容易赢”
它就会系统性偏向前者。
- 使用的是 全参数 DPO
这是最容易导致 catastrophic forgetting 的方式
总结#
两周的时间中,70% 用在了学习李沐和李宏毅老师的课程,剩余时间用于完成项目,因此看起来有些仓促。美中不足的就是 text-classification 没有调出更好的精度(终究是没找到 bug 在哪里),以及 RLHF 没有更深入地探究。