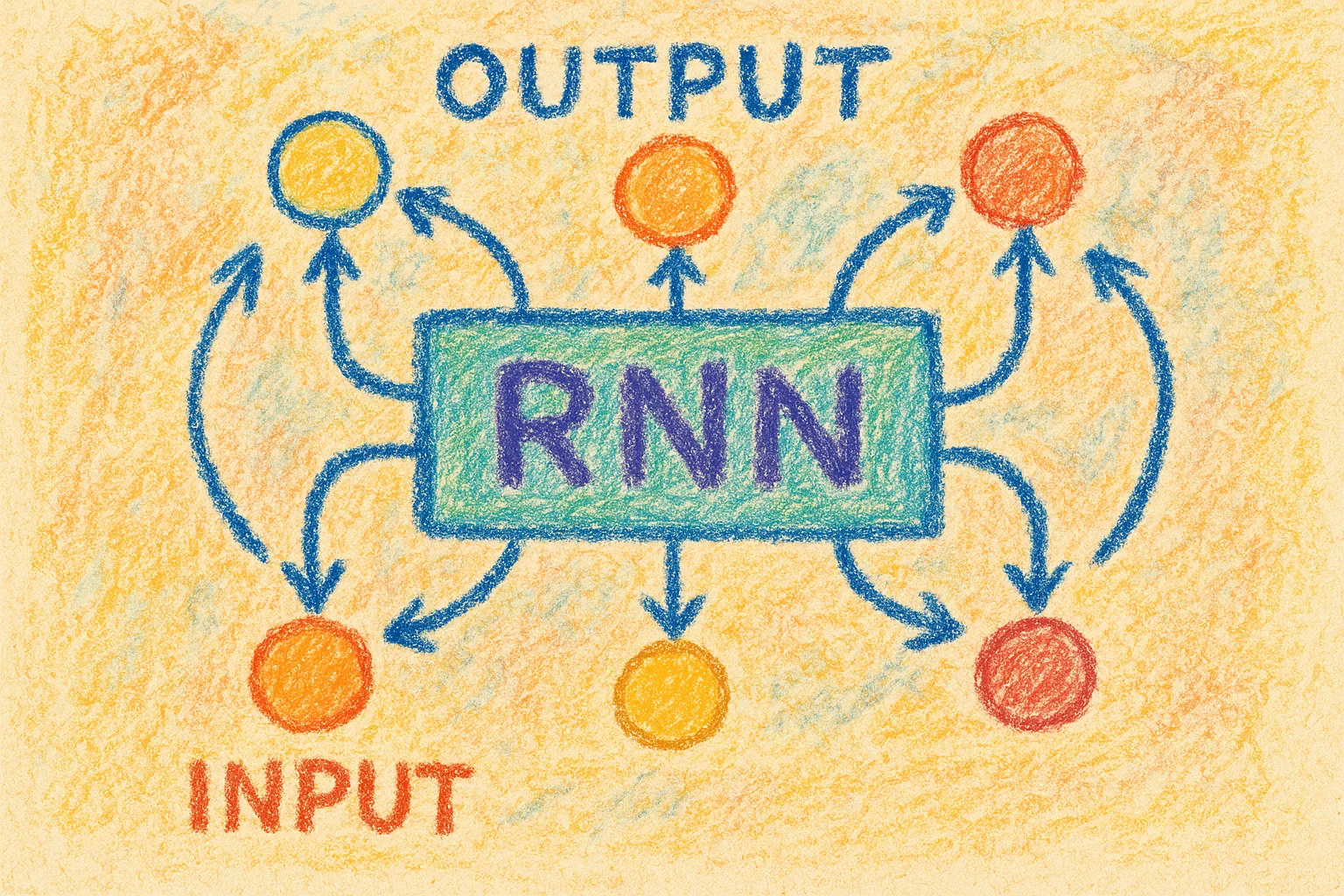
概述#
循环神经网络的一大应用就是序列生成(预测):模型每次试图预测已有的句子的下一个字是什么。当然,基于这个原理,还有其他各种应用,比如文本分类、机器翻译、问答机器人、句子成分打标(Tag)等。以下围绕序列生成解释 RNN.
RNN 的结构可以视作一个简单的分类模型加上了一个记忆(隐变量,h)。
这个“隐变量”,在原始的 RNN 实现中,其实就是上一时刻 MLP 的隐藏层 output 的快照。
每次向模型输入新的样本 (当前句子末尾的字)以及上一时刻隐变量的值 (相当于前面信息的摘要,也可以理解为模型的记忆),模型据此产生新的记忆值,覆写隐变量成为 ,并且以此来生成预测 。
形式化地,就是:
训练的时候,输入长度为 的序列(下标从 开始),使用“滑动窗口”让模型预测下一个字 (模型输出它认为的每个字出现的概率),并与实际的 进行交叉熵损失:。将总共 次预测的交叉熵损失取平均,得到 .
困惑度 Perplexity, PPL#
实际上,我们在 RNN 模型上使用的损失函数和评估指标,一般不是简单的平均交叉熵 ,而是使用困惑度: .
其好处就是:
- 数值更大,更容易梯度下降,同时对模型性能提升的衡量更加明显
- 更好解释:将 重新 回去,得到的其实是将每次模型「对正确词的预测概率 的倒数」取几何平均 —— ,也就可以解释为:困惑度是模型平均的 大小,也就是模型每次平均面临多少选择、有多纠结。 这样迂回地使用几何平均而不是直接求 的代数平均,可以避免数值过大影响精度(几何平均小于等于代数平均)。
梯度剪裁 Gradient Clipping#
由于 RNN 训练时的反向传播链较长(要沿着 一直反向传播,称为 Backpropagation Through Time, BPTT),容易产生梯度爆炸或者消失,因此通常需要进行梯度剪裁。
对于每个计算出来的梯度 ,我们给它的模长设一个上限 ,并通过这种方式进行限制:
实现细节#
数据预处理与训练#
对一个序列数据集,比如说一个长文本,我们首先进行 tokenize,就是分出 token(词元)。所有不同的 token 组成的集合就是一个 vocab,其大小是 vocab_size.
token 的分法多种多样,最省事的做法是按 character 或者空格分。当然也可以训练一个 tokenizer 来学习最佳的分词方式。
接着对 vocab 中的 token 进行 one_hot 编码(通常在进行 one_hot 之前还会做一个 token to integer 的映射,便于使用 torch.nn.functional.one_hot 函数),这会生成 vocab_size 个长度为 vocab_size 的向量。(这是叫 embedded_token 吗?不确定,请 GPT 帮忙解释一下)
这时候,长文本就可以变成一个长度为 的向量序列,每一个向量都是一个 one-hot 编码的 token。
为了给 RNN 进行小批量随机梯度下降训练,我们需要从数据集中分出 batches. 为此,需要先理清 RNN 是如何训练的。此处对概述中的介绍进行了细化,对于单个样本-标号对来说,训练流程如下:
- 给定一个长度为 的序列,取其前 项作为样本 ,后 项作为标号 .
- 模型从前到后,每时刻取当前位置的样本 ,与上一时刻的隐变量(或理解成“记忆”) 一起作为输入,得到模型新的隐变量 ,并据此生成预测 .
- 模型扫过整个 之后,会得到一个预测序列 (请注意,每个 其实都是一个 softmax 输出的概率分布,即一个长度为 vocab_size 的向量),我们希望它拟合实际的 ,因此在这两个序列之间计算前述的困惑度损失,并反向传播。
可以看出,对于单个 sample,RNN 需要迭代 次,而相比之下,原来的分类模型对于单个 sample 只需要进入网络一次即可得到损失。
这意味着对于每个 sample,RNN 的训练复杂度是以往的分类模型的 倍(其实这么比较并不公平,因为 RNN 语境下 sample 的数据量本来就是传统分类模型的 倍),但是我们仍然可以在一个 batch 里面进行多个 sample 间的并行。
所以,一个 batch 的迭代开销可以降低到和一个 sample 相同,就像以往的模型中一个 batch 里的不同 samples 也是并行的一样。
一些细节:我们的 token 经过 one-hot 编码之后变成了一个长为 vocab_size 的向量,因此我们的一个 batch 应当是 shape 为 时间 batch_size vocab_size 的一个三维张量。此处为了方便地在时间维度进行迭代,我们将时间维度转移到了第一维。
综上可知,在每个 epoch 中,我们需要:从整个长文本数据集(tokenized)中取出若干 batches,每个 batch 含有 batch_size 个 sample,而每个 sample 都是长度为 的 token 序列(即刚刚的 ),每个 token 都是长度为 vocab_size 的向量。此外,还需要给每个 sample 对应地取出它的标号,在这个语境就相当于 sample 右移一位的序列(即刚刚的 )。
在进一步阐述之前,我们先澄清几个量:
num_batches: 每个 epoch 要训练多少个 batch
batch_size: 如前文所述,每个 batch 含有几个 sample
num_steps: 即前文的 ,每个 sample 的序列长度
为了实现这样的“取 batch 逻辑”,我们大可以写个多重循环,每个 batch 我都去整个数据集中随机采样 batch_size 个 sample,然后每轮 epoch 总共采样 个 sample. 但这样会导致 samples 中存在大量重叠,没有必要;同时还会使我们每轮 epoch 训练成本很高,训练速度很慢。
一个更轻量的做法是:直接将数据集切分为长度为 num_steps 的小段,所有的小段作为这一个 epoch 的全部 samples,小段的总数量记为 num_subseqs.
然后,随机或者顺序地将这些 samples 分配给 num_batches 个 batch,使得每个 batch 含有 batch_size 个 sample. 这样做的话,每个 epoch 总共只会采样 个 sample,同时每个 token 都被不重复地扫描了一遍。
只不过直接这样做的话会导致每个 epoch 中 samples 的切分方法都一样,也就是在所有可能的 个 sample 中,每轮 epoch 都只有那恒定的 个 sample 被用来训练模型。解决方法是:在每次切分 batch 时,先在开头做一个随机的 offset,使等分的起始点随机偏移 个位置,这样每个 epoch 中,samples 的切分方法也不尽相同,允许模型接触所有可能的 samples,利于提高模型泛化性。